How To Find And Resolve Duplicate Content
21 April 2017
By Tovey
In this week’s How To Guide, we’ll be talking you through how to find duplicate content on your website and how to resolve the issue. We will be covering:
-
What is duplicate content?
-
Examples of Innocent Duplicate Content
-
How To Find Duplicate Content
-
How To Resolve Duplicate Content
-
Additional Tips
I) What is Duplicate Content?
Duplicate content is when similar content is found on multiple pages of either your own website or another. It can be pretty detrimental to your rankings because Search Engines can get a little confused and don’t know which page to display. Because they care about us and want to give us the best experience possible, Search Engines will rarely show multiple versions of the same content. So, while duplicate content isn’t an official penalty, your visibility may suffer as a result. What’s more, link equity can suffer too, as inbound links will likely be sent to multiple pieces of content, rather than just one. As inbound links are one of the main ranking factors, duplicate content can inadvertently impact your ranking in this way too.
Sometimes duplicate content is the work of lazy writers, copy and pasters and generally sloppy work. However, sometimes duplicate content on your website is unavoidable.
II) Examples of Innocent Duplicate Content Issues
1. Sites that have 2 separate versions – e.g. “www.domainname.com” and “domainname.com” (with and without the “www” prefix) or, similarly, the http:// vs https:// suffix.
2. E-commerce websites – Many different websites now sell the same items and will use the manufacturer’s original descriptions. Similarly, sites may sell the same product in slightly different forms or sizes but the description remains the same.
3. Sites which cover multiple locations – If you operate in multiple locations but your service or product is the same in both, the description is often the same. For instance, housing developers offering the same 4 bedroom new-build homes in multiple locations can often fall into the trap.
4. Sites with added parameters such as tracking parameters or sidebars.
5. Other people magpie-ing your content and not crediting you with a link (also known as ‘scraping’).
6. If a CMS creates printer-friendly pages of your website which Google thinks should rank.
There are several other causes but if you think you could be suffering from duplicate content issues, the most important thing to know is how to find duplicate content on your website and how to resolve it.
III) How To Find Duplicate Content
You can use Google Search Console to identify problems under “Search Appearance” then “HTML Improvements”. Here you can see any URLs that have duplicate titles or descriptions. However, if you want to know how to find duplicate content on your website the simplest way, it’s probably via Siteliner. Siteliner is a completely free tool and will reveal key issues including duplicate content, common content, broken links, inbound links and page power.
1. Go to http://siteliner.com/
2. Enter your URL
3. Click “Go” and let it work its magic.
4. Scroll down a little and follow the link that says “Click here to see your duplicate content”
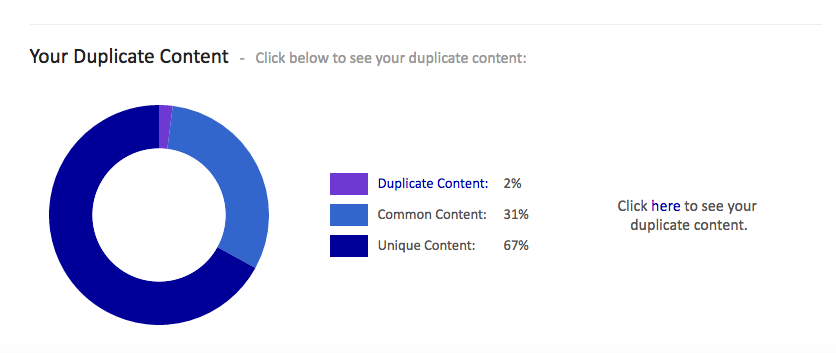
5. Site Liner will show you all the URLS with a match percentage, so you can identify which pages you need to work on.
IV) How To Resolve Duplicate Content
There are a few different ways to resolve duplicate content issues.
1. Set up a 301 redirect from the “duplicate” page to the original page of content. This will actually have a positive impact on the original.
2. Use canonical tags to tell Search Engines you know that this is duplicate content and you don’t want it to rank. Add rel=canonical to the HTML head of the duplicate versions of a page and all the link power should be directed to the original.
3. You can also add a self-referential rel=canonical link to your pages to safeguard against other content scrapers who might be getting SEO power from your content.
4. Add the Meta Robots tag content=”noindex,follow” to the HTML head of pages you don’t wish to rank.
V) Additional tips on how to avoid duplicate content issues
1. Always submit your pages to Search Console immediately, so Google indexes it as the original version.
2. Maintain consistency when internal linking across your website.
3. Add a note at the end of your articles requesting people link back to your original post if they reuse it.
4. If you are curating content or using sources from elsewhere on the web, always ensure that you transform that content into something new, unique and equally (if not more) useful so that Google recognises its value and keeps it in their index.
